
Im Software Department gestaltest du Robotik-Lösungen, die die Zusammenarbeit von Mensch und Maschine neu definieren. Du arbeitest mit modernster Technologie und setzt Standards, die die Branche verändern. Dabei entwickelst du nicht nur unsere Lösungen mit, sondern setzt neue Trends und treibst Innovationen voran. In einem agilen und interdisziplinären Team arbeitest du an spannenden Projekten. Mit klaren Scrum-Prozessen wie Daily Stand-ups, Sprint-Planungen und Reviews bleibst du flexibel und effizient. Die enge Zusammenarbeit mit anderen Fachbereichen ermöglicht es dir, Softwarelösungen zu entwickeln, die nicht nur technisch, sondern auch praktisch überzeugen. Hier findest du eine Umgebung, in der Kreativität und technologische Exzellenz Hand in Hand gehen. Wenn du Ideen Realität werden lassen möchtest und Spaß daran hast, Technologien auf ein neues Level zu bringen, wartet im Software Development Team bei NEURA genau die richtige Herausforderung auf dich.

GPU Cluster Engineer - Large-Scale AI Training Infrastructure (Human)
Neura Robotics GmbH • Metzingen
Gestalte die Zukunft der Mensch-Roboter-Kollaboration
-
Vollzeit
Metzingen
-
Du bist die zentrale Ansprechperson für NEURAs GPU‑Cluster-Infrastruktur – ein großskaliges AWS‑HyperPod‑Setup mit topmodernen GPU‑Instanzen für Foundation‑Model‑Training und kundenspezifische Fine‑Tuning‑Workloads.
-
Du entwickelst das Betriebsframework, baust Self‑Service‑Tools für die ML‑Teams und arbeitest direkt mit AWS zusammen, um die Plattform auf Hyperscaler‑Ebene mitzugestalten.
-
Dein Fokus liegt voll auf Cluster Engineering & Operations — nicht auf ML‑Forschung selbst, sondern darauf, dass die Leute, die forschen, eine extrem stabile, effiziente und leicht zugängliche Infrastruktur haben.
-
Aufsetzen, Konfigurieren und kontinuierliches Weiterentwickeln der HyperPod‑Cluster von NEURA, inkl. HyperPod/Slurm und HyperPod/EKS‑Orchestrierungsmodellen.
-
Design und Umsetzung von Strategien für Cluster-Stabilität: Node‑Failure‑Detection, automatische Job‑Recovery, Checkpoint‑Koordination und fehlertolerante Multi‑Node‑Training‑Workflows.
-
Aufbau eines Workload‑Priority‑Frameworks, das mehreren Teams und Use Cases – Pretraining, Fine‑Tuning, Kundenjobs – erlaubt, Clusterkapazität fair und effizient zu teilen.
-
Optimierung der End‑to‑End‑GPU‑Auslastung: Erkennen und Lösen von Bottlenecks in Compute, GPU‑Speicher, EFA‑Netzwerk und Storage‑Durchsatz.
-
Enge Zusammenarbeit mit den AWS HyperPod‑Produkt‑ und Engineering‑Teams: Issues eskalieren, Learnings aus einer der größten Deployments teilen und Anforderungen für die Roadmap platzieren.
-
Bereitstellung von Self‑Service‑Tools, damit ML‑Researchers und Engineers Trainingsjobs eigenständig starten, monitoren und managen können – ohne ständige Infrastrukturunterstützung.
-
Erstellung von Onboarding‑Dokus, Trainingsmaterial und internen Workshops, damit User effizient arbeiten, Best Practices einhalten und Kosten ihrer Workloads verstehen.
-
Infrastructure as Code ist für dich Standard. Jede Cluster‑Konfiguration, jede Änderung, jede Umgebung ist Code‑first.
-
Verantwortung für Kosten- und Kapazitätsstrategie: Spot‑Management, Reserved‑Instance‑Planung, Savings Plans und laufende AWS‑Commitment‑Verhandlungen.
- 5+ Jahre Erfahrung im Infrastructure‑ oder Systems‑Engineering, idealerweise mit Fokus auf GPU‑Cluster oder HPC‑Umgebungen.
- Tiefe praktische Erfahrung mit AWS HyperPod und AWS‑Instanzen; direkte Erfahrung mit HyperPod ist ein starker Vorteil.
- Solides Verständnis von Slurm und Kubernetes als Orchestrierungsschichten – und die Fähigkeit, ihre Trade‑offs für große GPU‑Workloads zu bewerten.
- Praktisches Wissen über Distributed Training – du weißt, was Durchsatz beeinflusst und wie man Probleme debuggt.
- Erfahrung in der Entwicklung von Self‑Service‑Tools und technischer Dokumentation für anspruchsvolle Endnutzer: Du machst komplexe Infrastruktur zugänglich, nicht nur funktionsfähig.
- Starkes Verständnis für Cloud‑Kostenmanagement im großen Maßstab: Spot‑Interruptions, Kapazitätsreservierungen, Kostenverteilung über Teams und Workloads.
- Wohlfühlen in der Zusammenarbeit über Teamgrenzen hinweg – deine Hauptpartner sind ML‑Forschende, aber auch Product, Finance und Cloud‑Vendors.
- Sehr gute Englischkenntnisse; Deutsch ist ein Plus.
Worauf du dich freuen kannst
Gestaltungsfreiheit und Agilität
Leistungsorientierte und eigenverantwortliche Arbeitskultur mit flachen Hierarchien sowie flexiblen Arbeitszeiten und 30 Tagen Erholungsurlaub.
Leidenschaft zu gewinnen
Ein leidenschaftliches und hochqualifiziertes Team aus internationalen Experten, die Roboterassistenten neu definieren wollen.
Attraktive Vergütung
Wettbewerbsfähiges Gehaltspaket plus spezielle Mitarbeiterrabatte.
One Team
Ob Sommerfest oder Firmen-Townhall-Meetings – Erfolge feiern wir gemeinsam.
Weiterentwicklung
Unterstützung bei deiner persönlichen und beruflichen Entwicklung.

Andre Jank
Unsere Unternehmenswerte. Die Eckpfeiler unseres Erfolgs.

Wir sind ein Team. Wir streben danach, Großes zu erreichen, indem wir den Erfolg unserer Kollegen und Partner fördern.

Wir streben nach technologischem Fortschritt, um Menschen ihre wertvolle Zeit für angenehme Tätigkeiten zurückzugeben.

Wir sind bestrebt, die Welt der Robotik zu revolutionieren, indem wir die Grenzen der Technologie täglich verschieben.

Durch offene Kommunikation und Transparenz leben wir ein hohes Maß an Wertschätzung.
Wir geben unser Bestes immer zwei Schritte voraus zu sein. Dies erreichen wir durch Empowerment, Handlungsfreiheit und Eigenverantwortung.

Der Mensch steht im Mittelpunkt all unseren Handelns.
Unser Standort

Unsere Headquarters in Metzingen und in Riederich sind das Herz unseres Unternehmens. Hier befinden sich nicht nur unsere Büros, sondern auch die Produktion, die Academy, die Logistik und die Tech Labs – alles vereint, um Ideen Wirklichkeit werden zu lassen. Riederich selbst ist ein kleiner, ruhiger Ort, nur einen Kilometer entfernt von Metzingen, einer Stadt mit ganz eigenem Charakter.
Metzingen ist weltweit als Outlet City bekannt und zieht Menschen aus aller Welt an. Hier kannst du exklusive Designerläden in einer entspannten, charmanten Umgebung genießen. Gleichzeitig bietet die Stadt Restaurants, Cafés und eine bodenständige schwäbische Gemütlichkeit – ideal, um nach der Arbeit zu entspannen.
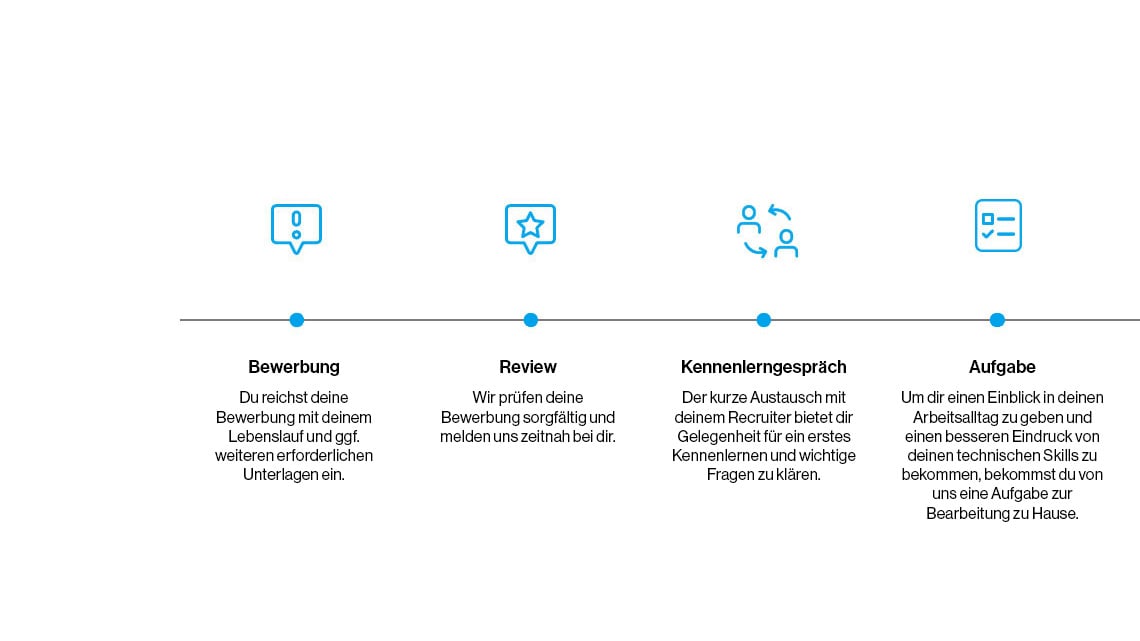
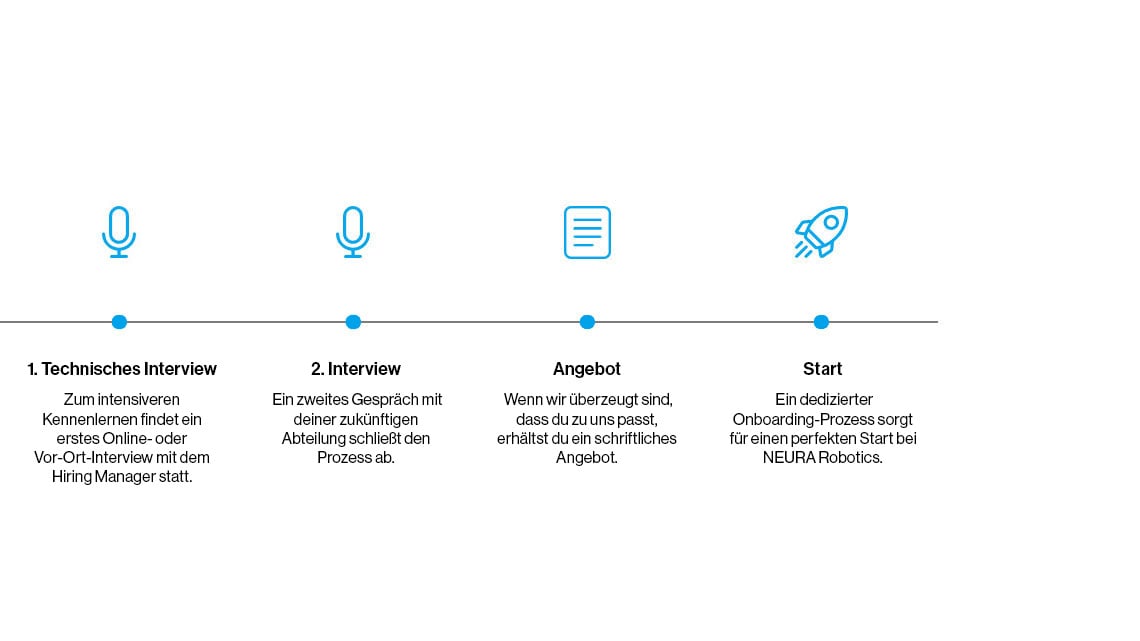
Bewerbungsprozess
Wir sorgen für einen transparenten und effizienten Ablauf und freuen uns darauf, dich während des Bewerbungsprozesses kennenzulernen.
Dein Blick in den Arbeitsalltag




Unsere Mission

Unser Ziel war es, den weltweit ersten kognitiven Roboter zu entwickeln, der mit Menschen arbeiten, von ihnen lernen und sie so zielgerichtet unterstützen kann. Genau das haben wir erreicht. Aber es kommt noch viel mehr!